Abstract
Tracking a point through a video can be a challenging task due to uncertainty arising from visual obfuscations, such as appearance changes and occlusions. Although current state-of-the-art discriminative models excel in regressing long-term point trajectory estimates—even through occlusions—they are limited to regressing to a mean (or mode) in the presence of uncertainty, and fail to capture multi-modality. To overcome this limitation, we introduce Generative Point Tracker (GenPT), a generative framework for modelling multi-modal trajectories. GenPT is trained with a novel flow matching formulation that combines the iterative refinement of discriminative trackers, a window-dependent prior for cross-window consistency, and a variance schedule tuned specifically for point coordinates. We show how our model’s generative capabilities can be leveraged to improve point trajectory estimates by utilizing a best-first search strategy on generated samples during inference, guided by the model’s own confidence of its predictions. Empirically, we evaluate GenPT against the current state of the art on the standard PointOdyssey, Dynamic Replica, and TAP-Vid benchmarks. Further, we introduce a TAP-Vid variant with additional occlusions to assess occluded point tracking performance and highlight our model’s ability to capture multi-modality. GenPT is capable of capturing the multi-modality in point trajectories, which translates to state-of-the-art tracking accuracy on occluded points, while maintaining competitive tracking accuracy on visible points compared to extant discriminative point trackers.
News
- October 21, 2025
Initial release of the code and paper now available!
Features
Multi-modal prediction of point trajectories
(Top row) 100 randomly sampled trajectories of a single tracked point from GenPT. The first image shows the full path of each sampled trajectory. GenPT captures the multi-modality present in uncertain regions of the video. When tracking uncertainty is high, the majority of predictions are clustered around regions where the point is most likely to be. Occasionally, spurious (but valid) predictions can occur due to feature similarity elsewhere in the frame. (Bottom row) Ground truth for top row.
Improving estimates via best-first search on generated samples
Point trajectory estimates can be improved by utilizing a best-first search strategy on generated samples during inference, guided by the model’s own confidence of its predictions in each window of observation.
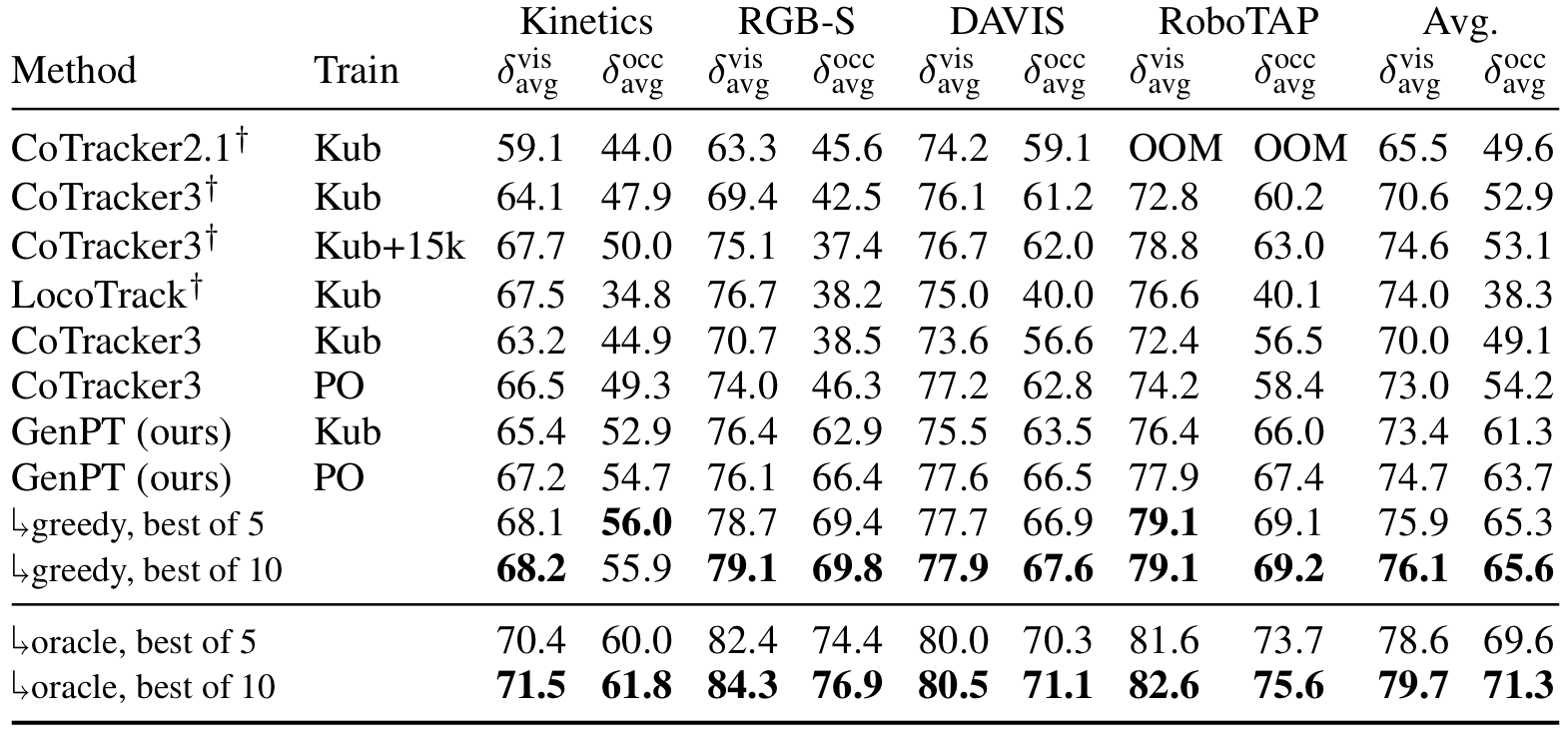
Excellent tracking accuracy during occlusions
Shown above is the tracking performance of various models on a variant of the TAP-Vid benchmark, where a 100-pixel wide black bar is translated across each video in various directions. Results are averaged across directions. Also shown are results when taking the best of N sampled trajectories for each sliding window, using either greedy search guided by the model’s predicted confidence or an oracle (i.e. their distance to the ground truth). The oracle results highlights our model’s performance ceiling. † Using pre-trained model weights.
Our PointOdyssey-trained model outperforms all models on δ_occ_avg by a significant margin, managing a 9.5% lead over our PointOdyssey-trained CoTracker3, a 10.6% lead over CoTracker3 (Kub + 15k), a 10.8% lead over CoTracker3 (Kub), a 14.1% lead over CoTracker2.1, and a 25.4% lead over LocoTrack. Our Kubric-trained model maintains a similar δ_occ_avg gap with most models, except there is a larger 12.2% lead when compared with our identically-trained CoTracker3.


Citation
Mattie Tesfaldet, Adam W. Harley, Konstantinos G. Derpanis, Derek Nowrouzezahrai, and Christopher Pal. Generative Point Tracking with Flow Matching. arXiv preprint, 2025.
Bibtex format:
@article{tesfaldet2025,
title = {{Generative Point Tracking with Flow Matching}},
author = {Tesfaldet, Mattie and Harley, Adam W and Derpanis, Konstantinos G and Nowrouzezahrai, Derek and Pal, Christopher},
journal = {arXiv preprint},
year = {2025}
}